Archive
You are currently browsing the archives for the Uncategorized category.
By John Byers
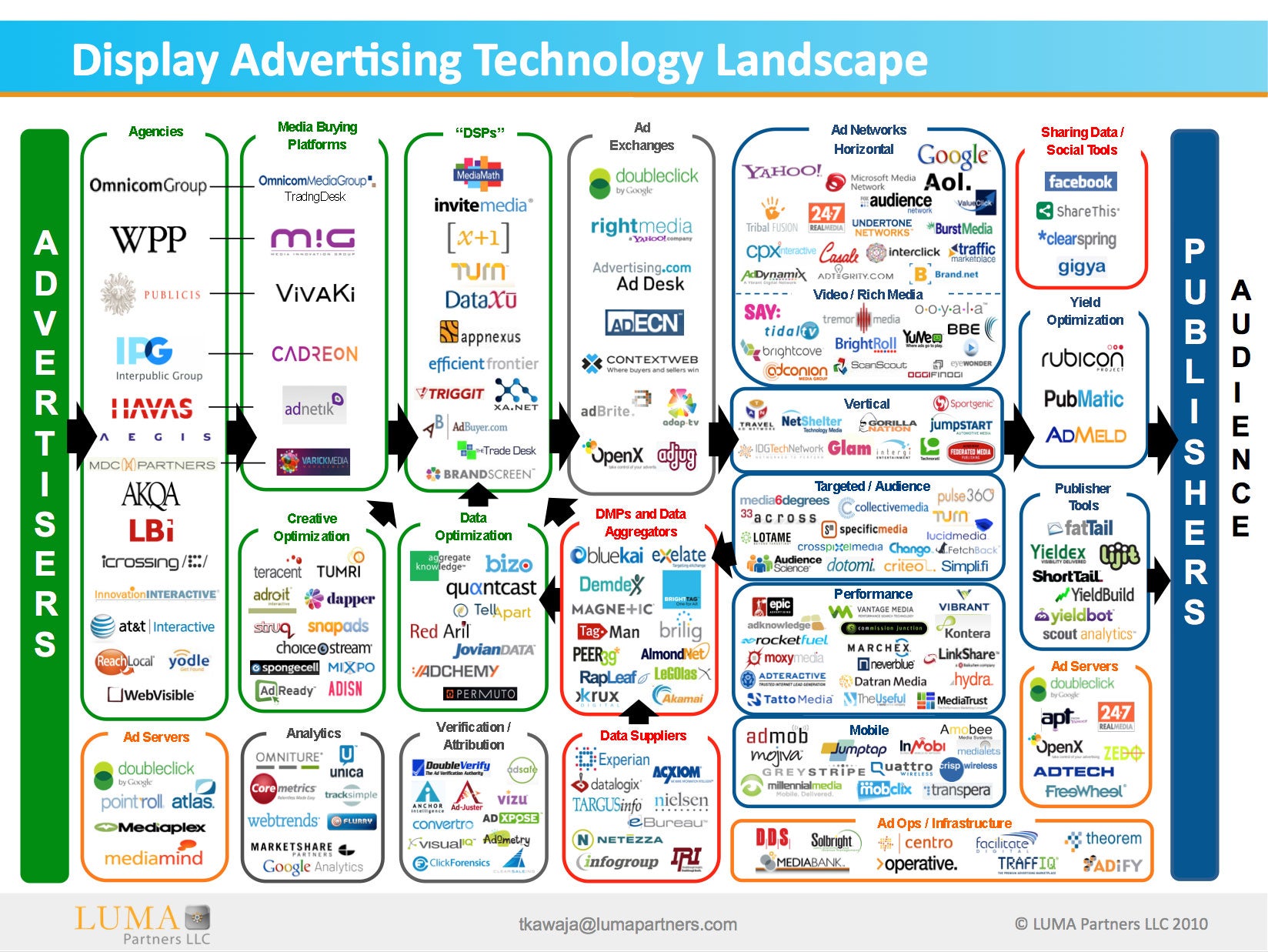
Advertising back in the pre-Internet days was pretty simple. Ad agencies schmoozed with advertisers (think “Mad Men”), designed ad copy for their clients, and negotiated with publishers to buy ad spots. But recently, and especially in the last five years, the landscape of online advertising has quietly been transformed. Most people think of Google and maybe DoubleClick when it comes to new business models, but the reality is that a staggeringly complex ecosystem (graphic by a VC firm) has emerged.
Not only are there hundreds of firms depicted in this figure, but there are probably over a dozen distinct business models, most of them predicated on hard-core computer science. For example, on top of the ad exchanges are DSPs (demand-side platforms), like Turn, that use blackbox optimization and behavioral and demographic targeting to drive ad buys across exchanges, often using real-time bidders. Another interesting model is DMPs (data management platforms), like BlueKai, that do massive-scale data analytics and data mining based on historical advertiser performance to optimize campaigns. These companies are pushing the envelope both with respect to systems design, since the throughput and latency requirements of matching ad slots to users in real-time on such a massive scale is daunting; as well as in data analytics, where mined datasets are running into tens of TB or more. Another aspect is a silent erosion of privacy, as some firms are cookie-ing users with attributes like “in-market for a new car”, others are buying impressions based on these cookies (cookie retargeting), and still others are computing joins of separate observations to build large databases of user information.
Once Congress figures out what to do about the debt ceiling, they’ll eventually turn their attention back to online advertising practices, so all of this technology as well as the privacy implications will be back in the news. Also, research in this area, especially as relates to privacy, is still in the very early stages, so it could be a worthwhile venue to investigate.
(Full disclosure: the post-er is a director at a “Data Optimization” online advertising company (that is still successfully flying a little too stealthily to be on the ecosystem chart 🙂 )).
By matta
The July IEEE Communications magazine has a special issue on Future Internet Architectures (FIA). The first article by Raj Jain et al. gives a survey of some FIA research projects in the US, Europe and Asia:
ieeexplore.ieee.org/iel5/35/5936142/05936152.pdf?arnumber=5936152
From reading this article, you get a sense that we're still doing things backwards 😉 The authors write that step 1 is coming up with innovations, then step 2 putting them into an overall network architecture. Really! Why should we believe that these individual innovations would "fit" together. Remember, the NAT was an "innovation", and all sorts of patches we did to the Internet over the last 30-40 years. Do they fit? If so, the research community wouldn't have rallied behind "clean-slate" FIA!
The government is funding research that proposed design without a theory - but it proposed to come up with "an underlying theory supporting the design". Hmm, shouldn't theory come first? 🙂
And people talk about "data are named instead of their location (IP addresses)". Well, in CS, names have always been structured to find where things are. So, a real theory would think about the similarities and differences between names and addresses, e.g. that addresses are just shorter names to make it more efficient to carry them in packet headers...
And people keep confusing storage management (a la DTN) with communication... We need a theory that tells us when to "store" vs. just forward.
The article ends with "even those collaborative ones like in FIA program, put more emphasis on a specific attribute or a specific set of problems. It seems to be a tough problem to handle many challenges in a single architecture design." And we need a "comprehensive theory in the research process rather than designing based only on experiences." I agree. The community can't seem to be able to think really clean-slate.
Based on our research so far, it seems that (really!) clean-slate thinking would give you a very simple architecture with one recursive block that has only two protocols. Meet RINA: http://csr.bu.edu/rina/ 🙂
By Mark Crovella
Here is an interesting NYT article about "Search Engine Optimization" (SEO) applied to Google. It seems that certain service categories like local locksmiths are getting flooded by bogus websites that are fronts for phone banks. So an unsuspecting customer who searches for "locksmith boston" will get a large number of hits that essentially all go to the same service in the end.
There are a number of research questions here, for example:
- For how many categories of services is this a problem?
- For any given category, how can one sort the "real" from the "fake" sites?
The nice thing about these questions is that you can do the research just by typing google queries and looking at the results. The main observation I would start from is that any attempt to overwhelm search results must rely heavily on automation, and therefore incorporate simple patterns that can be detected.
For example, "boston locksmith" yields top hits with domain names bostonlocksmiths.net, bostonlocksmith.com, bostonlocksmith.org, boston-locksmiths.us, and quite a few more following that pattern. Similarly, doing a search for "dc locksmith" yields domains like "dclocksmith.org", etc.
Another example is the HTML content of web pages. For example take a look at http://www.minneapolis-locksmith.us/ and http://www.bostonlocksmith.us/ and http://www.chicagolocksmith.us/. The similarities here should be easily detected.
Finally, Google can help you directly. Google image search has come a long way in allowing "query by example". Searching for the graphic on the left hand side of http://www.bostonlocksmith.us/ finds the same image used on locksmith sites in about a dozen cities. (It also finds the original image which was appropriated for this graphic -- coming from a professor in Manchester England!)
Could be a neat project to "reverse-engineer" these SEO strategies!
By Azer Bestavros
Google's Chief Security Officer (yes, companies now have a CIO and a CSO), Eran Feigenbaum, stirred a debate recently when he questioned the obsession of the US (and other governments) about data sovereignty in outsourced environments. He is quoted as saying: “It is an old way of thinking. Professionals should worry about security and privacy of data, rather than where it is stored."
http://www.scmagazine.com.au/News/260041,google-who-cares-where-your-data-is.aspx
What do you think? Should it matter *where* data is stored (or for that matter where the pipes carrying it happen to be)? Assuming a cloud provider meets what it promises in its SLA (availability, persistence, proper authentication/encryption, etc.), can you think of vulnerabilities that necessiates that data resides on "American Soil"?
The other interesting statement by Google's CSO regards the need for encryption of data at rest (i.e., on disk as opposed to end-to-end through an application): "It is a false sense of security. Crypto people do a good job at cryptography, but a really bad job at key management."
By Mark Crovella
The last IPv4 addresses have been allocated by IANA. It seems unavoidable that soon, some new hosts are going to need to be IPv6 only.
One set of stakeholders that have resisted IPv6 has been content providers. Content providers have been concerned that if they enable IPv6, users with older software will not be able to access their sites, or will have poor performance. This has lead to a "not me first!" attitude -- a classic suboptimal Nash equilibrium in which no single content provider has incentive to switch, since they may lose customers to other providers.
An interesting experiment designed to break out of this suboptimal equilibrium is for all the parties to agree to a simultaneous switch of strategies. That has led to "World IPv6 Day" -- June 8 -- in which most of the largest content providers will simultaneously enable IPv6 for one day, and "see what happens." The idea is that maybe IPv6 won't be as bad as some people think, and even if there are problems, we might learn some things to help us address them.
Estimates are that roughly 0.05% of users could have difficulty accessing participating sites on this day. In case you are concerned, Microsoft has a fix available here.
I won't be online myself much that day. But I would be very interested in any observations that anyone has about unusual Internet behavior that day! Please comment if you notice anything interesting.
By Azer Bestavros
Here is an interesting Op-Ed in today's NYT, which touches on the point I made in my earlier post entitled "Ignorance is Bliss".
http://www.nytimes.com/2011/05/23/opinion/23pariser.html
I have been harping on this for a while, but Eli Pariser (of MoveOn.org) puts it very eloquently: "There is a new group of gatekeepers in town, and this time, they’re not people, they’re code."
In Jon Crowcroft's talk at BU earlier this month, I hinted to this issue -- getting information through a social network reduces entropy -- and alluded to the need for better "personalization" technology and algorithmics. Pariser's point is that we should not trust editorial responsibility (the control of information flow) to code. If we do, then the Internet would have turned things around 360 degrees -- by allowing us to bypass "an elite class of editors", only to let code decide what people would see and hear about the world.
Related to (and influencing my thinking about) the above is the long-held position that "Code is Law" by Lawrence Lessig.
Computer Science is quickly becoming a social science!
By Mark Crovella
Vern Paxson is the 2011 SIGCOMM award winner. This is a great choice, and well deserved. Vern has worked mainly in the areas of Internet Measurement and Security. Of course, often those areas intersect, and he has done some of the best work at that intersection. Vern's work is notable for for asking and answering interesting questions through careful and thorough acquisition and analysis of data (think 'Freakonomics' for the Internet). And he's given back to the community in many ways. Congratulations Vern!
By Azer Bestavros
This is a very intriguing study about how social media/interactions may be warping "crowd wisdom" -- defined as "the statistical phenomenon by which individual biases cancel each other out, distilling hundreds or thousands of individual guesses into uncannily accurate average answers". In this study, researchers told test participants about their peers’ guesses. As a result, their group insight (a.k.a., group regression to the mean) "went awry". You can think about this as introducing dependencies, and hence biases in the sample statistics.
http://www.wired.com/wiredscience/2011/05/wisdom-of-crowds-decline/
I should try this in a test in CS-350!
Perhaps related to the above is the mounting criticism of "personalization" as introducing biases in what (say) search engines return to different people for the same exact query -- Google now is personalizing Google search and Google News...
There is something to be said for having crowds have consistent views of the world...
By Mark Crovella
This is an interesting analysis of MSFT vs REL vs CentOS.
http://www.theregister.co.uk/2011/05/17/microsoft_and_centos/
I'm continually intrigued by how the location of 'value' shifts in the IT industry. It seems that software has this constant potential for being re-architected, and as a result, where the problem lies, shifts. This article suggests that the real money-making opportunity in cloud computing right now is in management (ie, as opposed to in OSes or CPUs). This makes sense to me and jibes with what I saw when I worked in industry.
It reminds me of how IBM, which once made oodles of money selling OSes and CPUs, eventually moved 'up' the value chain to selling managed 'solutions'. I think this was a remarkable reinvention. I wonder if Microsoft can and will eventually do something similar.
By Azer Bestavros
Here are mine -- comments?
Y. Chu, S.G. Rao, and H. Zhang. A Case for End System Multicast. In Proceedings of ACM Sigmetrics, June 2000.
http://academic.research.microsoft.com/Publication/247484/a-case-for-end-system-multicast
Lixin Gao and Jennifer Rexford. Stable Internet routing without global coordination. In Proceedings of ACM Sigmetrics, June 2000.
http://academic.research.microsoft.com/Publication/234493/stable-internet-routing-without-global-coordination
Thomas Bonald and Laurent Massoulié. Impact of fairness on Internet performance. In Proceedings of ACM Sigmetrics, June 2001.
http://academic.research.microsoft.com/Publication/680569/impact-of-fairness-on-internet-performance
Steven H. Low, Larry Peterson, and Limin Wang. Understanding TCP vegas: a duality model. In Proceedings of ACM Sigmetrics, June 2001.
http://academic.research.microsoft.com/Publication/115673/understanding-tcp-vegas-a-duality-model
{kind=link}